Pivots and Joins
Contents
Pivots and Joins#
from datascience import *
from cs104 import *
import numpy as np
%matplotlib inline
1. Review groups#

“President Barack Obama receives a gift from Saudi King Abdullah at the start of their bilateral meeting in Riyadh, Saudi Arabia, on June 3, 2009. The large gold medallion was among several gifts given that day that were valued at $34,500, the State Department later said” –CBS News
# Read in all gifts, and tidy up table by removing nan values and relabeling columns
all_gifts = Table().read_table('data/obama-gifts.csv')
all_gifts = all_gifts.where('donor_country', are.not_equal_to('nan')) #clean up and remove the nans
all_gifts = all_gifts.select('year_received', 'donor_country', 'value_usd')
all_gifts = all_gifts.relabeled('year_received', 'Year')
all_gifts = all_gifts.relabeled('donor_country', 'Country')
all_gifts = all_gifts.relabeled('value_usd', 'Value')
all_gifts.sample(8)
| Year | Country | Value |
|---|---|---|
| 2010 | Nigeria | 8315 |
| 2009 | Pakistan | 1200 |
| 2012 | Azerbaijan | 405 |
| 2011 | Suriname | 1575.79 |
| 2016 | China | 2200 |
| 2011 | Indonesia | 970 |
| 2015 | Nigeria | 2260 |
| 2012 | Austria | 650 |
# We'll also create a small subset of our Obama Gifts dataset.
# It contains 3 countries, 3 years, 7 gifts
gifts = all_gifts.where('Year', are.contained_in([2009,2010,2011,2012]))
gifts = gifts.where('Country', are.contained_in(make_array('Denmark', 'Egypt', 'Finland')))
gifts = gifts.sort('Year')
gifts
| Year | Country | Value |
|---|---|---|
| 2009 | Denmark | 388 |
| 2009 | Egypt | 630 |
| 2009 | Denmark | 340 |
| 2010 | Finland | 445 |
| 2010 | Egypt | 356 |
| 2010 | Egypt | 380 |
| 2011 | Denmark | 485 |
gifts.group('Year')
| Year | count |
|---|---|
| 2009 | 3 |
| 2010 | 3 |
| 2011 | 1 |
gifts.group('Country')
| Country | count |
|---|---|
| Denmark | 3 |
| Egypt | 3 |
| Finland | 1 |
gifts.group('Year', sum)
| Year | Country sum | Value sum |
|---|---|---|
| 2009 | 1358 | |
| 2010 | 1181 | |
| 2011 | 485 |
all_gifts.group('Year', sum)
| Year | Country sum | Value sum |
|---|---|---|
| 2009 | 571164 | |
| 2010 | 122626 | |
| 2011 | 233730 | |
| 2012 | 75307.8 | |
| 2013 | 198508 | |
| 2014 | 1.40138e+06 | |
| 2015 | 1.10529e+06 | |
| 2016 | 147903 |
gifts.group('Country', max)
| Country | Year max | Value max |
|---|---|---|
| Denmark | 2011 | 485 |
| Egypt | 2010 | 630 |
| Finland | 2010 | 445 |
The largest gifts given to Obama:
all_gifts.group('Country', max).sort('Value max', descending=True)
| Country | Year max | Value max |
|---|---|---|
| Saudi Arabia | 2016 | 570000 |
| Italy | 2016 | 124000 |
| Qatar | 2015 | 110000 |
| Brunei | 2016 | 73200 |
| Gabon | 2014 | 52695 |
| Ghana | 2016 | 48000 |
| Kuwait | 2015 | 42000 |
| Brazil | 2015 | 40000 |
| Myanmar (Burma) | 2016 | 26220 |
| Pakistan | 2015 | 23615 |
... (113 rows omitted)
gifts.group(make_array('Year', 'Country'))
| Year | Country | count |
|---|---|---|
| 2009 | Denmark | 2 |
| 2009 | Egypt | 1 |
| 2010 | Egypt | 2 |
| 2010 | Finland | 1 |
| 2011 | Denmark | 1 |
gifts.group(make_array('Year', 'Country'), sum)
| Year | Country | Value sum |
|---|---|---|
| 2009 | Denmark | 728 |
| 2009 | Egypt | 630 |
| 2010 | Egypt | 736 |
| 2010 | Finland | 445 |
| 2011 | Denmark | 485 |
all_gifts.group(['Year', 'Country'], max).sort('Value max', descending=True)
| Year | Country | Value max |
|---|---|---|
| 2014 | Saudi Arabia | 570000 |
| 2015 | Saudi Arabia | 522972 |
| 2009 | Saudi Arabia | 132000 |
| 2009 | Italy | 124000 |
| 2015 | Qatar | 110000 |
| 2015 | Brunei | 73200 |
| 2013 | Brunei | 71468 |
| 2016 | Saudi Arabia | 56720 |
| 2011 | Gabon | 52695 |
| 2009 | Ghana | 48000 |
... (336 rows omitted)
2. Pivots#
Summarize data that has been grouped by two variables in a grid.
gifts
| Year | Country | Value |
|---|---|---|
| 2009 | Denmark | 388 |
| 2009 | Egypt | 630 |
| 2009 | Denmark | 340 |
| 2010 | Finland | 445 |
| 2010 | Egypt | 356 |
| 2010 | Egypt | 380 |
| 2011 | Denmark | 485 |
With only two parameters in pivot, the values are counts.
gifts.pivot('Country', 'Year')
| Year | Denmark | Egypt | Finland |
|---|---|---|---|
| 2009 | 2 | 1 | 0 |
| 2010 | 0 | 2 | 1 |
| 2011 | 1 | 0 | 0 |
gifts.pivot('Year', 'Country')
| Country | 2009 | 2010 | 2011 |
|---|---|---|---|
| Denmark | 2 | 0 | 1 |
| Egypt | 1 | 2 | 0 |
| Finland | 0 | 1 | 0 |
With four parameters used in pivot,
The first is the horizontal column labels
The second is the vertical row labels
The third is the column used as values in the grid
The fourth is the aggregation function used for the values in the grid
gifts.pivot('Year', 'Country', 'Value', sum)
| Country | 2009 | 2010 | 2011 |
|---|---|---|---|
| Denmark | 728 | 0 | 485 |
| Egypt | 630 | 736 | 0 |
| Finland | 0 | 445 | 0 |
gifts.pivot('Year', 'Country', 'Value', max)
| Country | 2009 | 2010 | 2011 |
|---|---|---|---|
| Denmark | 388 | 0 | 485 |
| Egypt | 630 | 380 | 0 |
| Finland | 0 | 445 | 0 |
A pivot from our past: Temperatures in Greenland#
We spent some time working with our Upernavik climate data.
greenland_climate = Table.read_table('data/climate_upernavik.csv')
greenland_climate
| Year | Month | Air temperature (C) | Sea level pressure (mbar) | Precipitation (millimeters) |
|---|---|---|---|---|
| 1873 | 9 | 0.4 | 9999.9 | 15 |
| 1873 | 10 | -5.3 | 9999.9 | 34 |
| 1873 | 11 | -9.4 | 9999.9 | 30 |
| 1873 | 12 | 999.99 | 9999.9 | 29 |
| 1874 | 1 | -29.6 | 9999.9 | 9 |
| 1874 | 2 | -19.6 | 9999.9 | 22 |
| 1874 | 9 | 0.1 | 1010.7 | 68 |
| 1874 | 10 | -5.4 | 1002.7 | 24 |
| 1874 | 11 | -8 | 1010.5 | 15 |
| 1874 | 12 | -8.4 | 1005.1 | 69 |
... (1355 rows omitted)
greenland_climate = Table.read_table('data/climate_upernavik.csv').where('Year', are.above(1876))
greenland_climate = greenland_climate.relabeled('Precipitation (millimeters)', "Precip (mm)")
tidy_greenland = greenland_climate.where('Air temperature (C)', are.not_equal_to(999.99))
tidy_greenland = tidy_greenland.where('Sea level pressure (mbar)', are.not_equal_to(9999.9))
tidy_greenland
| Year | Month | Air temperature (C) | Sea level pressure (mbar) | Precip (mm) |
|---|---|---|---|---|
| 1877 | 1 | -21.1 | 994.9 | 24 |
| 1877 | 2 | -26.5 | 1008.2 | 26 |
| 1877 | 3 | -17.8 | 1013.4 | 84 |
| 1877 | 4 | -12 | 1023.6 | 6 |
| 1877 | 5 | -1.7 | 1019.4 | 9 |
| 1877 | 6 | 1.4 | 1011.8 | 5 |
| 1877 | 7 | 4.6 | 1011.5 | 9 |
| 1877 | 8 | 5.2 | 1019.8 | 29 |
| 1877 | 9 | 3 | 1009 | 51 |
| 1877 | 10 | -2.8 | 1006.2 | 23 |
... (1221 rows omitted)
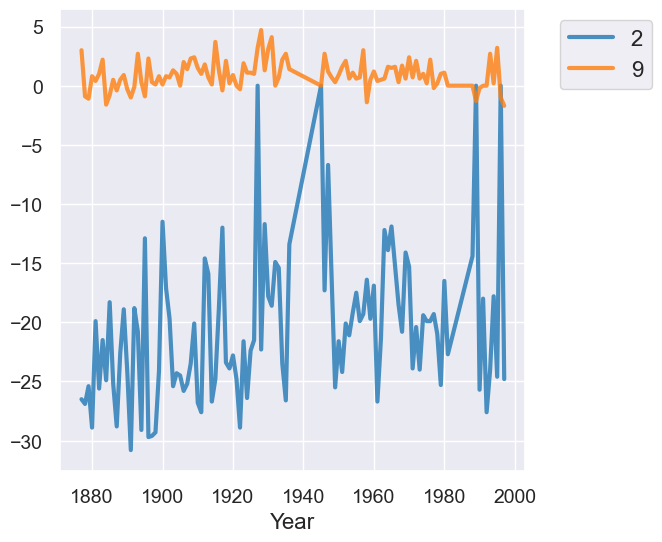
When plotting line graphs, we needed separate columns for each month. A pivot gives us a table with that format.
temps_by_month = tidy_greenland.pivot('Month', 'Year', 'Air temperature (C)', np.mean)
temps_by_month
| Year | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1877 | -21.1 | -26.5 | -17.8 | -12 | -1.7 | 1.4 | 4.6 | 5.2 | 3 | -2.8 | -10 | -19.2 |
| 1878 | -22.9 | -26.9 | -19.6 | -13 | -5.6 | 1.9 | 3.2 | 4.3 | -0.9 | -4 | -2 | -3.7 |
| 1879 | -13.5 | -25.4 | -21.3 | -13 | -2.7 | 0 | 5.2 | 5.8 | -1.1 | -5.5 | -8.2 | -16.5 |
| 1880 | -22.6 | -28.9 | -22.7 | -10.7 | -3.1 | 2.2 | 5.6 | 2.9 | 0.8 | -0.3 | -9.4 | -14.6 |
| 1881 | -13.6 | -19.9 | -26.4 | -12.8 | -3.1 | 1.3 | 5.3 | 4.2 | 0.4 | -2.8 | -9.4 | -17.5 |
| 1882 | -27.6 | -25.6 | -24.9 | -14.8 | -3.2 | 3.1 | 3.3 | 4.1 | 1 | -6.1 | -12.1 | -17.1 |
| 1883 | -19.9 | -21.5 | -12.7 | -12.8 | -1.9 | 3 | 6.2 | 4.4 | 2.2 | -4.1 | -8.9 | -21.1 |
| 1884 | -26.1 | -24.9 | -22.7 | -13.6 | -6.4 | 1.6 | 5.1 | 3.2 | -1.6 | -5.1 | -11.8 | -20.7 |
| 1885 | -15.9 | -18.3 | -23 | -12.8 | -2 | -0.4 | 5.2 | 5.2 | -0.8 | -4.6 | -13.2 | -18.5 |
| 1886 | -24.2 | -25.2 | -23.7 | -18.4 | -2.8 | 1.2 | 5.3 | 4.2 | 0.5 | -6.3 | -11.9 | -18.6 |
... (97 rows omitted)
two_months = temps_by_month.select('Year', '2', '9')
two_months.show(5)
| Year | 2 | 9 |
|---|---|---|
| 1877 | -26.5 | 3 |
| 1878 | -26.9 | -0.9 |
| 1879 | -25.4 | -1.1 |
| 1880 | -28.9 | 0.8 |
| 1881 | -19.9 | 0.4 |
... (102 rows omitted)
two_months.plot('Year')
3. Joins#
Let’s hand pick a few of our favorite gifts.
best_gifts = gifts.take(0,1,2,3).drop("Year")
best_gifts
| Country | Value |
|---|---|
| Denmark | 388 |
| Egypt | 630 |
| Denmark | 340 |
| Finland | 445 |
If you’re curious what they are, here are shortened descriptions for the four we chose.
best_gifts.with_columns("Gift description",
make_array('Book "Restoring the Military Balance"',
'Yellow alabaster bowl',
'Photograph of Her Majesty and His Royal Highness',
'Hand-blown blue glass bird'))
| Country | Value | Gift description |
|---|---|---|
| Denmark | 388 | Book "Restoring the Military Balance" |
| Egypt | 630 | Yellow alabaster bowl |
| Denmark | 340 | Photograph of Her Majesty and His Royal Highness |
| Finland | 445 | Hand-blown blue glass bird |
Here is some other info about countries, specifically the GDP from each country during Obama’s first year in office. (GDP is gross domestic product, a measure of the value of the final goods and services produced in a country.)
We obtained this data from the World Bank and IMF sites.
gdp = Table().with_columns(
'Country Name', make_array('Denmark', 'Egypt', 'Egypt', 'Greece'),
'GDP (Billion $)', make_array(321, 189, 198, 331),
'Source', make_array('World Bank', 'World Bank', 'IMF', 'World Bank'))
gdp
| Country Name | GDP (Billion $) | Source |
|---|---|---|
| Denmark | 321 | World Bank |
| Egypt | 189 | World Bank |
| Egypt | 198 | IMF |
| Greece | 331 | World Bank |
Can we combine best_gifts with info about the countries like GDP?
Join will let us merge data from two tables by pairing together rows from each that share a common property. Here we’ll merge a table of gifts with a table of GDP information about the countres giving gifts.
best_gifts.join('Country', gdp, 'Country Name')
| Country | Value | GDP (Billion $) | Source |
|---|---|---|---|
| Denmark | 388 | 321 | World Bank |
| Denmark | 340 | 321 | World Bank |
| Egypt | 630 | 189 | World Bank |
| Egypt | 630 | 198 | IMF |
4. Open-ended exploration#
Suppose we had the following question: Is there any association between a country’s GDP and the total value of gifts they gave to President Obama?
The World Bank provides GDP data we can use.
gdp = Table().read_table('data/gdp.csv')
gdp.show(3)
| Country Name | Country Code | Indicator Name | Indicator Code | 1960 | 1961 | 1962 | 1963 | 1964 | 1965 | 1966 | 1967 | 1968 | 1969 | 1970 | 1971 | 1972 | 1973 | 1974 | 1975 | 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 | 1996 | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | Unnamed: 66 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Aruba | ABW | GDP (current US$) | NY.GDP.MKTP.CD | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 4.05587e+08 | 4.87709e+08 | 5.96648e+08 | 6.95531e+08 | 7.64804e+08 | 8.72067e+08 | 9.58659e+08 | 1.08324e+09 | 1.24581e+09 | 1.32067e+09 | 1.37989e+09 | 1.53184e+09 | 1.66536e+09 | 1.72291e+09 | 1.87318e+09 | 1.89665e+09 | 1.96201e+09 | 2.04413e+09 | 2.25475e+09 | 2.35978e+09 | 2.46983e+09 | 2.67765e+09 | 2.84302e+09 | 2.55363e+09 | 2.45363e+09 | 2.63799e+09 | 2.61508e+09 | 2.72793e+09 | 2.79106e+09 | 2.96313e+09 | 2.9838e+09 | 3.09218e+09 | 3.20223e+09 | 3.31006e+09 | 2.49665e+09 | nan | nan |
| Africa Eastern and Southern | AFE | GDP (current US$) | NY.GDP.MKTP.CD | 2.12906e+10 | 2.18085e+10 | 2.3707e+10 | 2.821e+10 | 2.61188e+10 | 2.96822e+10 | 3.22391e+10 | 3.35146e+10 | 3.65215e+10 | 4.18283e+10 | 4.48626e+10 | 4.94789e+10 | 5.35148e+10 | 6.96008e+10 | 8.60578e+10 | 9.16492e+10 | 9.11246e+10 | 1.03416e+11 | 1.15345e+11 | 1.34671e+11 | 1.70654e+11 | 1.74387e+11 | 1.67266e+11 | 1.74918e+11 | 1.60134e+11 | 1.36297e+11 | 1.52518e+11 | 1.86145e+11 | 2.0414e+11 | 2.17539e+11 | 2.53224e+11 | 2.73403e+11 | 2.38255e+11 | 2.36527e+11 | 2.4012e+11 | 2.69637e+11 | 2.68414e+11 | 2.82185e+11 | 2.65814e+11 | 2.62172e+11 | 2.83925e+11 | 2.58819e+11 | 2.6487e+11 | 3.52659e+11 | 4.38834e+11 | 5.12211e+11 | 5.75921e+11 | 6.61179e+11 | 7.08287e+11 | 7.19217e+11 | 8.60478e+11 | 9.64418e+11 | 9.73043e+11 | 9.83937e+11 | 1.00368e+12 | 9.24253e+11 | 8.82355e+11 | 1.02065e+12 | 9.91022e+11 | 9.97534e+11 | 9.21646e+11 | 1.0821e+12 | nan |
| Afghanistan | AFG | GDP (current US$) | NY.GDP.MKTP.CD | 5.37778e+08 | 5.48889e+08 | 5.46667e+08 | 7.51111e+08 | 8e+08 | 1.00667e+09 | 1.4e+09 | 1.67333e+09 | 1.37333e+09 | 1.40889e+09 | 1.74889e+09 | 1.83111e+09 | 1.59556e+09 | 1.73333e+09 | 2.15556e+09 | 2.36667e+09 | 2.55556e+09 | 2.95333e+09 | 3.3e+09 | 3.69794e+09 | 3.64172e+09 | 3.47879e+09 | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | nan | 4.05518e+09 | 4.51556e+09 | 5.22678e+09 | 6.20914e+09 | 6.97129e+09 | 9.74788e+09 | 1.01093e+10 | 1.24162e+10 | 1.58567e+10 | 1.78051e+10 | 1.99073e+10 | 2.01464e+10 | 2.04971e+10 | 1.91342e+10 | 1.81166e+10 | 1.87535e+10 | 1.80532e+10 | 1.87995e+10 | 2.01161e+10 | nan | nan |
... (263 rows omitted)
Data wrangling: Let’s subset to the columns we actually need and make these values more readable.
gdp_2008 = Table().with_columns(
'Country Name', gdp.column('Country Name'),
'2008 GDP Billion USD', gdp.column('2008') / 1e9
)
gdp_2008.show(3)
| Country Name | 2008 GDP Billion USD |
|---|---|
| Aruba | 2.84302 |
| Africa Eastern and Southern | 708.287 |
| Afghanistan | 10.1093 |
... (263 rows omitted)
Let’s use group to sum up the values of gifts given by each country.
all_gifts.show(5)
| Year | Country | Value |
|---|---|---|
| 2009 | Mexico | 400 |
| 2009 | Japan | 1495 |
| 2009 | United Kingdom | 16510 |
| 2009 | Algeria | 500 |
| 2009 | Denmark | 388 |
... (608 rows omitted)
gifts_by_country = all_gifts.drop('Year').group('Country', sum)
gifts_by_country.show(5)
| Country | Value sum |
|---|---|
| Afghanistan | 9263 |
| Algeria | 4312.28 |
| Argentina | 3977.98 |
| Armenia | 2985 |
| Australia | 4365.48 |
... (118 rows omitted)
Let’s join these two datasets.
joined = gifts_by_country.join('Country', gdp_2008, 'Country Name')
joined
| Country | Value sum | 2008 GDP Billion USD |
|---|---|---|
| Afghanistan | 9263 | 10.1093 |
| Algeria | 4312.28 | 171.001 |
| Argentina | 3977.98 | 361.558 |
| Armenia | 2985 | 11.662 |
| Australia | 4365.48 | 1055.13 |
| Austria | 1275 | 432.052 |
| Azerbaijan | 11503 | 48.8525 |
| Bahrain | 10494 | 25.7109 |
| Bangladesh | 390 | 91.6313 |
| Benin | 12289.9 | 9.78774 |
... (91 rows omitted)
joined.scatter('2008 GDP Billion USD', 'Value sum')
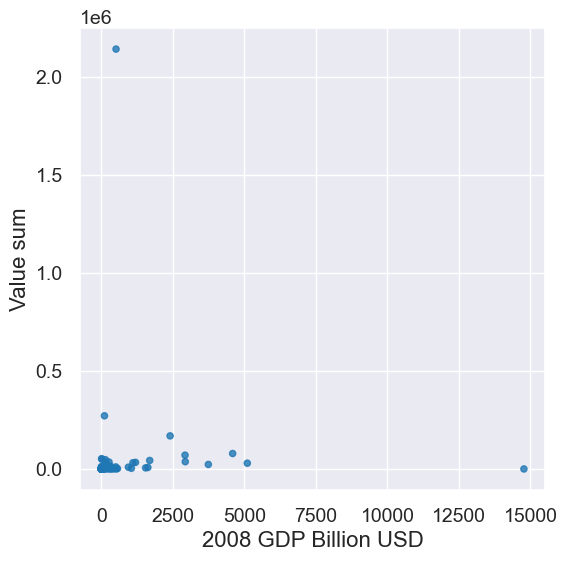
The scatter plot doesn’t show much because most of the data is in a very tiny part of the graph. It’s hard to tell whether the other points are outliers or part of some trend. In this case, one handy tool is to take the log of each x-value and y-value.
Recall that for a number \(n\), \(log(n) = a\) such \(10^a = n\). Here are some values to illustrate how logarithms work:
n |
log(n) |
|---|---|
1 |
0 |
10 |
1 |
100 |
2 |
1,000 |
3 |
10,000 |
4 |
100,000 |
5 |
1,000,000 |
6 |
10,000,000 |
7 |
100,000,000 |
8 |
1,000,000,000 |
9 |
joined.scatter('2008 GDP Billion USD', 'Value sum', xscale='log', yscale='log')
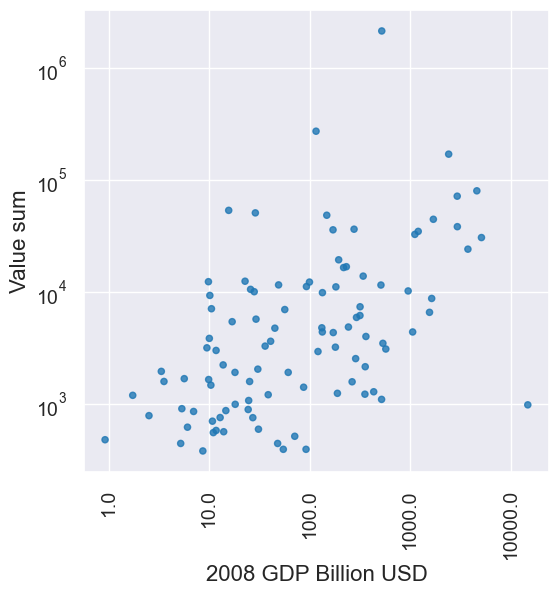
That makes the points more evenly distributed across both axes of the plots, and it makes any correlation jump out. We can do a lot with log-log plots like this, but for us, we will be happy to just use it to make the correlation more apparent in this one example.
What about the relationship between oil production and gift values? You can find oil production for every country or region of the world here.
# Compute the average oil production during the years 2009-2016.
oil = Table().read_table('data/oil_production_by_country.csv')
oil_for_years = oil.where('Year', are.between_or_equal_to(2009, 2016))
oil_by_entity = oil_for_years.drop('Code', 'Year').group('Entity', np.average)
oil_by_entity.sort('Oil production (TWh) average', descending=True)
oil_by_entity.sample(10)
| Entity | Oil production (TWh) average |
|---|---|
| British Virgin Islands | 0 |
| Maldives | 0 |
| Kyrgyzstan | 0.629978 |
| Yemen | 97.5896 |
| Other Caribbean (BP) | 33.8952 |
| Cape Verde | 0 |
| Germany | 31.7684 |
| Other Northern Africa (BP) | 0.0804617 |
| Costa Rica | 0 |
| Greece | 1.07807 |
joined_oil = gifts_by_country.join('Country', oil_by_entity, 'Entity')
joined_oil.scatter('Oil production (TWh) average', 'Value sum')
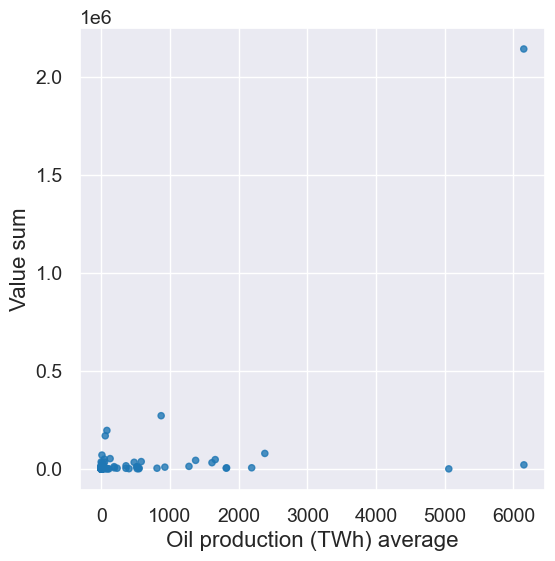
plot = joined_oil.scatter('Oil production (TWh) average', 'Value sum',
xscale='log', yscale='log')
plot.set_xlim(1/1e3, 1e5)
plot.set_ylim(1e2, 1e6)
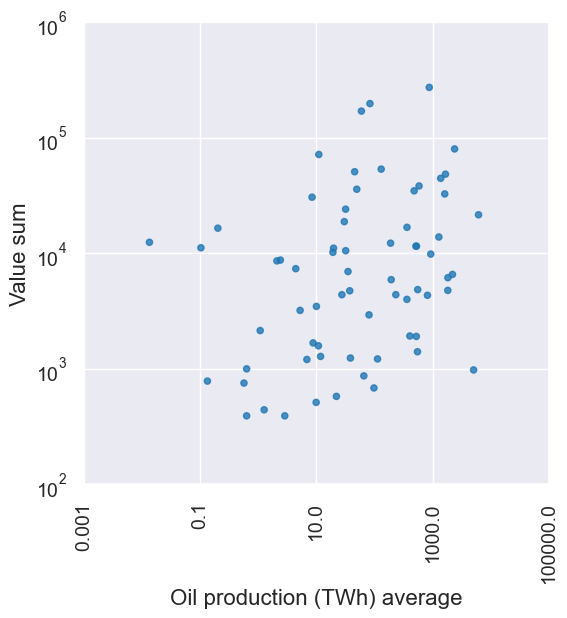
If you’re curious about the top oil producers in the world…
joined_oil.sort('Oil production (TWh) average', descending=True)
| Country | Value sum | Oil production (TWh) average |
|---|---|---|
| Russia | 21474 | 6153.07 |
| Saudi Arabia | 2.14279e+06 | 6151.13 |
| United States | 974 | 5059.72 |
| China | 79786.5 | 2381.96 |
| Canada | 6541.36 | 2190.7 |
| United Arab Emirates | 6125 | 1825.73 |
| Iraq | 4755.99 | 1819.56 |
| Kuwait | 48265 | 1660.07 |
| Mexico | 32546.2 | 1612.68 |
| Brazil | 44409.7 | 1374.56 |
... (102 rows omitted)
Q: Brainstorm some alternative variables we might want to examine correlations between?
Norms of gift giving? Political alliances? Trade deals?
Could we track if this relationship changes over time?
In this class, we’re going to be moving towards some more of these open-ended data questions.