In this lab we will look at data from the Social Security Administration 1 about the popularity of baby names from 1880-2021. In doing so, you will gain experience with the following:
matplotlib libraryBefore you begin, clone this week’s repository in the usual manner:
git clone https://evolene.cs.williams.edu/cs134-labs/23xyz3/lab06.git ~/cs134/lab06where your CS username replaces 23xyz3.
If you are using a personal computer, for this lab you will need to
have installed matplotlib. This was part of the personal
machine setup instructions. The lab machines are already configured for
you.
split() and trim()Define a function called trim that takes one argument:
line (a string). If line ends with a newline
character, then trim should return a new string that is
identical to line, but without the final newline character.
Otherwise, it should just return line.
>>> trim("Hello there!\n")
'Hello there!'
>>> trim("Hello there!!")
'Hello there!!'
>>> len(trim("")) # >>> trim("")
0 # returns '', but note that empty string doesn't display in runtests/when-run-as-a-scriptDefine a function called split that takes one argument:
comma_separated_string (a string). It should return a list
of its component substrings (i.e. the strings between the commas).
Here are some examples of its usage:
>>> split('a,b,c,d')
['a', 'b', 'c', 'd']
>>> split('alpha,bravo,charlie')
['alpha', 'bravo', 'charlie']
>>> split('alpha')
['alpha']
>>> split("")
[]Be sure to test your Pre-Lab functions with several edge cases!
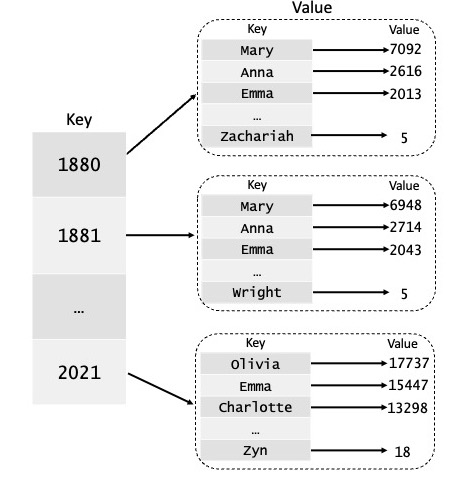
The Social Security Administration collects data on the frequency of
first names assigned at birth in the U.S. In the
data/namesDataAll.csv data file, you will find
comma-delimited records containing this data. Some notes on the format
of this data:
year,name,sex,number”,
where
year is 1880 to 2021name is 2 to 15 characterssex is M (male) or F (female), andnumber is the number of occurrences of the name.For reference, here are the first few lines of the file:
1880,Mary,F,7065
1880,Anna,F,2604
1880,Emma,F,2003
1880,Elizabeth,F,1939
1880,Minnie,F,1746
1880,Margaret,F,1578To effectively process the data from this file, we will use the two
helper functions we developed during our Pre-Lab: trim()
and split().
At the start of runtests.py, you will find two useful
examples of the ways we will organize the above data in this lab: name
tables and year tables.
A name table tells us how many times a newborn baby
was given a particular first name in a particular year. A name
table is implemented as a dict whose
keys are strs (the baby names) and whose
values are ints (the number of babies that
were given that name). In runtests.py, the function
example_name_table1 returns the following example of a
name table:
{'William': 1000, 'Lida': 19, 'Iris': 3}This means that in a particular year, 1000 babies were named William, 19 babies were named Lida, and 3 babies were named Iris.
A year table associates each year with its respective name table:
A year table is implemented as a dict whose
keys are ints (the years) and whose
values are dicts (the name table
associated with each year). In runtests.py, the function
example_year_table1 returns the following example of a
year table:
{1974: {'William': 4000, 'Lida': 20, 'Iris': 3},
1975: {'William': 3000, 'Lida': 14, 'Iris': 2},
1976: {'William': 2000, 'Lida': 10, 'Iris': 5},
1977: {'William': 1000, 'Lida': 19, 'Iris': 7},
1978: {'William': 500, 'Lida': 13, 'Iris': 4},
1979: {'William': 200, 'Lida': 16, 'Iris': 1}}This means that:
Using the helper functions from the Pre-Lab, trim and
split, complete the implementation of the function
read_names in names.py. When given a filename
(e.g. data/namesDataAll.csv), this function should read the
contents of that CSV file. It should also create and return a
year table (a dict of dicts, see the previous section “Organizing the Data” for specifics)
containing the data found in the file. When you read in the data, make
sure you convert both the years and frequencies to integers. If
multiple entries exist for a name in a given year (such as an entry for
the same name as both M and F), the totals for the name should be summed
in the dictionary.
You can test your implementation in interactive Python:
>>> from names import *
>>> year_table = read_names("data/namesDataAll.csv")
>>> year_table[2021]["Emily"]
6547
>>> year_table[1880]["Emily"]
210
>>> 1900 in year_table
True
>>> 1600 in year_table
False
>>> len(year_table[1880])
1889Alternatively, you can type the following into the Terminal:
python3 runtests.py q1Implement the name_frequency function in
names.py, which takes three arguments:
year_tablenameints called yearsIt should return a list of ints
corresponding to the frequency of the provided name across the specified
years. If a year does not exist in the year table or a name does not
exist in the name table associated with a particular year, you should
use the value 0 for that year in your list.
You can test your implementation in interactive Python:
>>> from runtests import *
>>> from names import *
>>> name_frequency(example_year_table1(), "William", [1977, 1978, 1979])
[1000, 500, 200]
>>> name_frequency(example_year_table1(), "Lida", [1977, 1979])
[19, 16]Alternatively, you can type the following into the Terminal:
python3 runtests.py q2To further demonstrate that your implementation of
name_frequency is correct, modify the function
example_year_table2 in runtests.py so that it
creates and returns a year table that might catch errors that
example_year_table1 does not catch. Then, add at
least one new test of your own design to
runtests.py that uses your new example year table (we have
provided an incomplete def statement called
my_name_frequency_test in the YOUR EXTRA TESTS
section for you to complete).
When creating your new example year table and associated test(s),
think about what cases the original table isn’t capturing. For instance,
the names “William”, “Lida”, and “Iris” appear in every name
table, but this doesn’t have to be the case. Would your code for
name_frequency still work correctly if the name “Lida”
didn’t appear in the 1978 name table or if the year 1234 did not exist
in the data?
Implement the function letter_frequency, which takes two
arguments:
year_tableint called year. You may assume
that year is a key in
year_table.It should return a list of integer frequencies indicating how many babies received a name starting with each letter. Remember to take the frequency of the name into account, as well; that is, if “Mary” shows up 50 times, the letter “M” should be incremented by 50 when processing “Mary”.
The resulting list returned by your function should have 26 entries corresponding to the frequency of each letter in the alphabet in alphabetical order. For example, in your resulting list, entry 0 should correspond to the frequency of names that start with “A”, index 1 should correspond to the frequency of names that start with “B”, and so on. You may assume that every name starts with a capital letter. If no names started with a particular letter, then the list element corresponding to that letter should be 0.
You can test your implementation in interactive Python:
>>> from runtests import *
>>> from names import *
>>> letter_frequency(example_year_table1(), 1978)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 13, 0, 0, 0, 0, 0, 0, 4, 0, 0, 0, 500, 0, 0, 0]
>>> letter_frequency(example_year_table1(), 1979)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 16, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 200, 0, 0, 0]Alternatively, you can type the following into the Terminal:
python3 runtests.py q3To further demonstrate that your implementation of
letter_frequency is correct, please add at least
one new test to runtests.py (we have provided an
incomplete def statement called
my_letter_frequency_test in the
YOUR EXTRA TESTS section). Your test(s) should use the year
table that you created in example_year_table2().
Again, when creating your test(s), think about what cases the original table isn’t capturing. For instance, the names “William”, “Lida”, and “Iris” all begin with different letters. Does your code still work when provided with a year table that contains several names that start with the same letter?
Implement the function plot_name_frequency in
names.py.
This function takes three arguments:
year_table: a year table (see the previous section “Organizing the Data” for the definition
of a year table)name: a str specifying a particular baby
nameyears: a list of ints,
specifying the years that we want to plotThis function need not return anything. However, it
should produce an image saved at name_freq_NAME.png (where
NAME is replaced with the appropriate baby name) that plots
the year (x-axis) vs. the frequency of the specified baby name in that
year (y-axis) using a line plot. For grading purposes, we will be
looking for name_freq_Mark.png, which can be generated
using the command python3 runtests.py final.
We have provided a partial implementation of
plot_name_frequency, however it requires you to write
additional code so that the variables x_values and
y_values are initialized and assigned the appropriate
values.
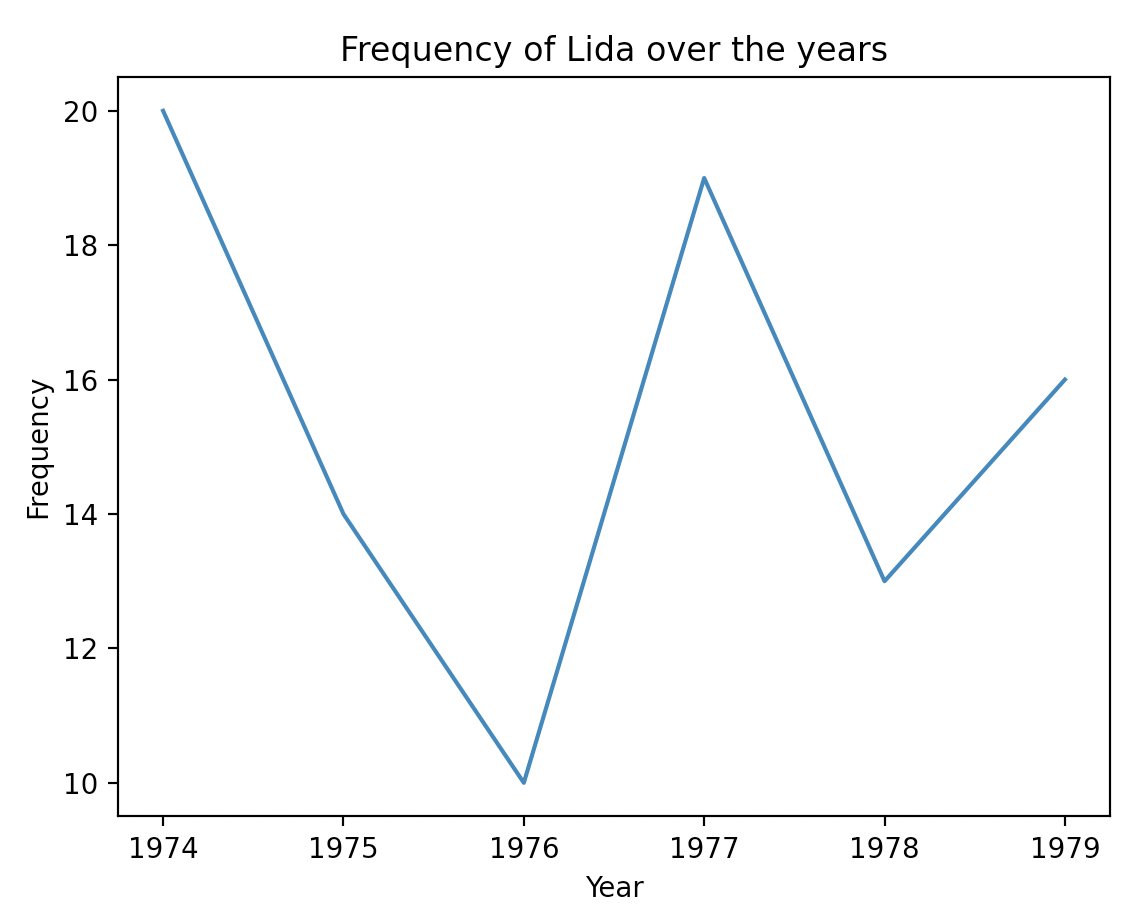
When implemented correctly, the plot showing the frequency of the
name “Lida” over the time period covered by
example_year_table1 will look like the following:
You can verify that your code produces the same figure by typing the following into interactive Python:
>>> from runtests import *`
>>> from names import *
>>> plot_name_frequency(example_year_table1(), "Lida", [1974, 1975, 1976, 1977, 1978, 1979])Alternatively, you can type the following into the Terminal:
python3 runtests.py q4Implement the function plot_letter_frequency in
names.py.
The plot_letter_frequency function takes two
arguments:
year_table: a year table (see the previous section “Organizing the Data” for the definition
of a year table)year: an int that specifies the year that
we are interested in analyzingThis function need not return anything. However, it
should produce an image saved at letter_freq_YEAR.png (with
YEAR replaced by the appropriate year) that plots first
initials (x-axis) vs. the frequency of that initial in the specified
year (y-axis) using a bar plot. For grading purposes, generate a
letter_freq_1960.png file with the plot for the year
1960, which can be generated using the command
python3 runtests.py final.
We have provided a partial implementation of
plot_letter_frequency, however it requires you to write
additional code so that the variables x_values and
y_values are initialized and assigned the appropriate
values.
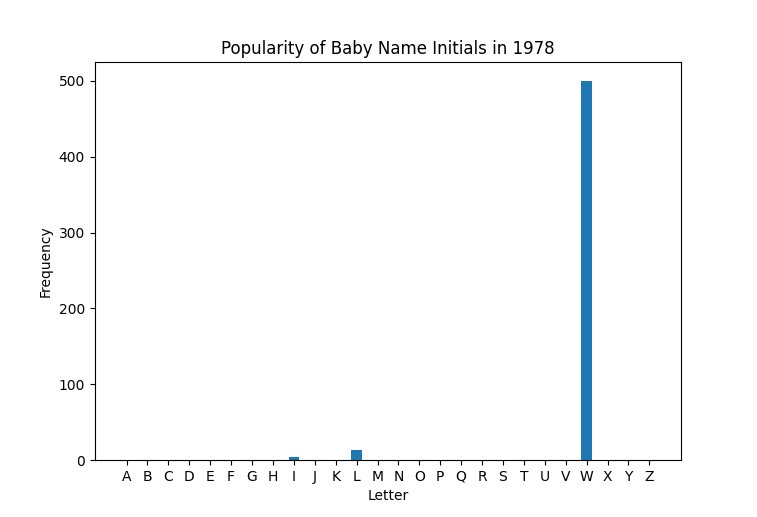
When implemented correctly, this should be the plot comparing the
frequency of initial letters in the year 1978, according to the data
provided by example_year_table1:
You can verify that your code produces the same figure by either typing the following into interactive Python:
>>> from runtests import *
>>> from names import *
>>> plot_letter_frequency(example_year_table1(), 1978)Alternatively, you can type the following into the Terminal:
python3 runtests.py q5Once your code is working, you can use it to visualize trends in how Americans have named their babies for the past century and a half. For instance, we can plot the popularity of the name Emma from 1880-2021 in interactive Python:
>>> from names import *
>>> year_table = read_names("data/namesDataAll.csv")
>>> years = list(range(1880, 2022))
>>> plot_name_frequency(year_table, name, years)You should see the following graph pop-up:
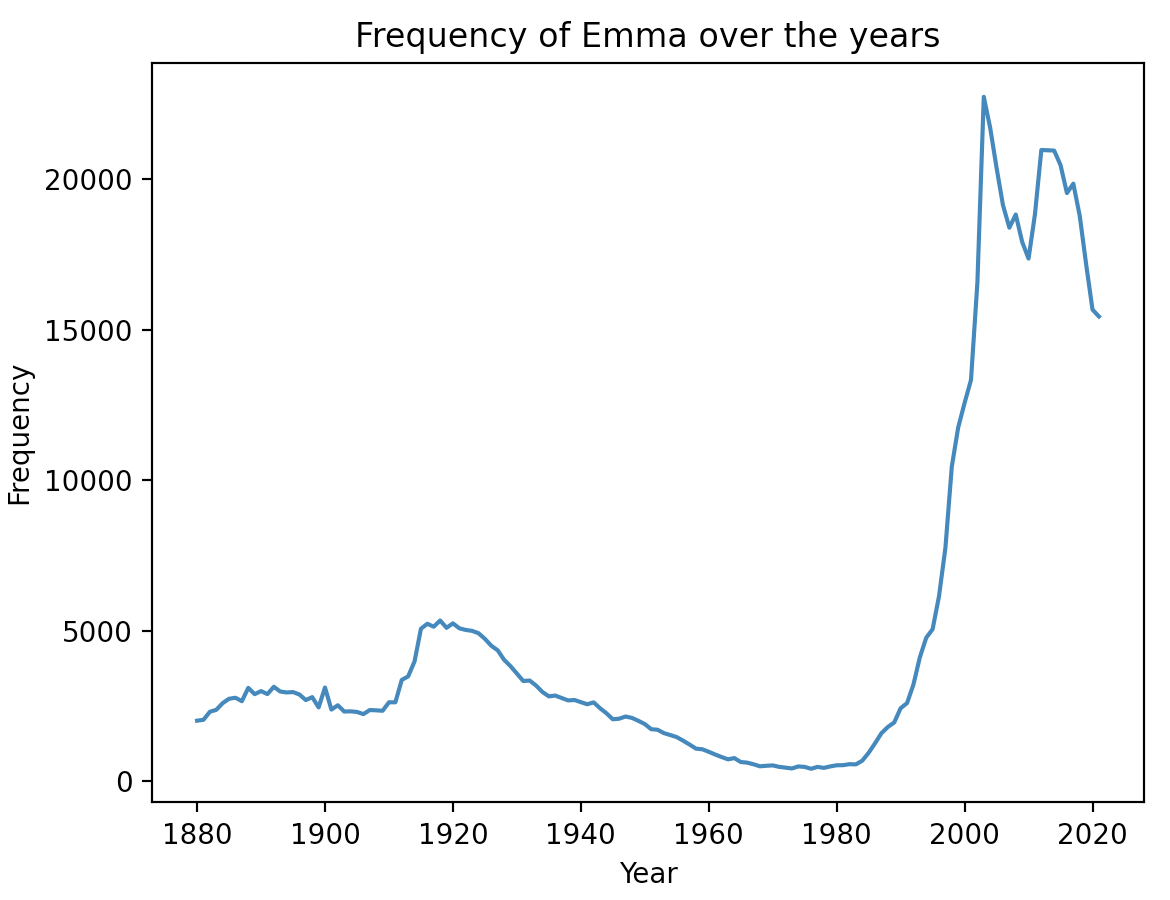
Note the surge in popularity around the year 2002, which is when Rachel named her baby “Emma” on the sitcom Friends.
Alternatively, you can generate this plot by typing the following into the Terminal:
python3 runtests.py q6 EmmaIf you replace “Emma” with any other name, it will use your code to plot the popularity of that name over the same time period. Make sure that you start the name with a capital letter!
As a final step, let’e explore how the frequency of first initials
has changed over time. One interesting way to investigate this trend is
by using an animated graph that cycles through the years in our data
set. The code is provided for you to handle the animation. All you need
to do is run python3 animation.py. However, this won’t work
until your implementations in names.py are correct!
Your final output should look like this (but with the plot updating for each year over time):
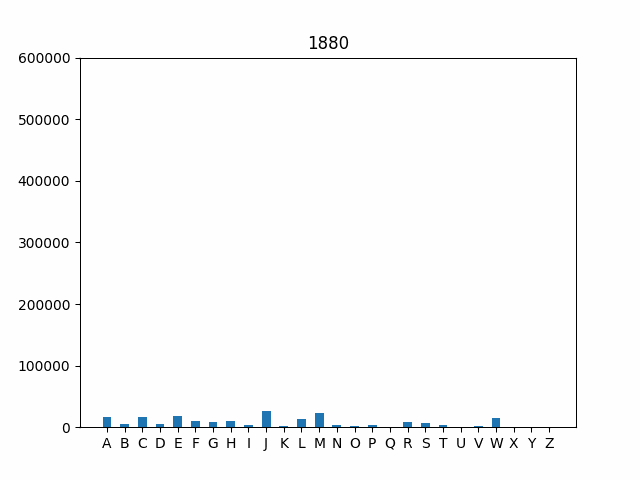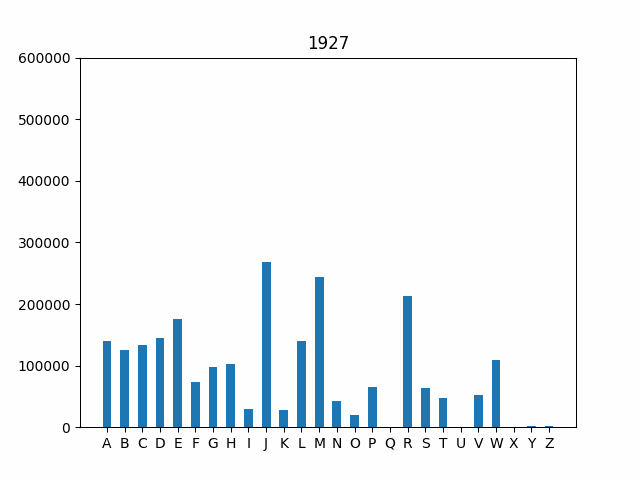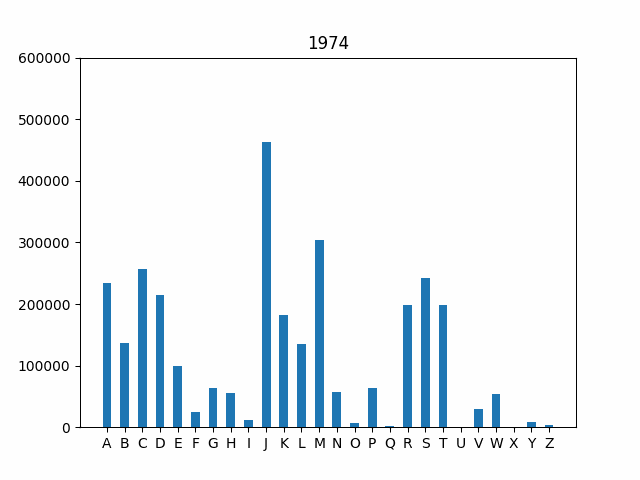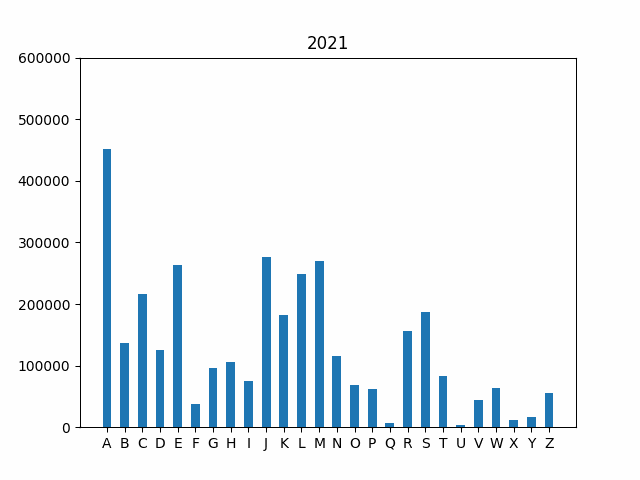
Because the graphs show the absolute number of babies with a particular initial, you can also get a sense for the periods in American history when birth rates spiked. For instance, note that the bars grow substantially during the post-WWII Baby Boom from 1946 to 1964.
Note: Ensure that the image in
name_freq_Mark.png shows the plot for the name
Mark, and the image in letter_freq_1960.png
shows the plot for the year 1960, so that we may grade it.
Both of these images can be generated using the command
python3 runtests.py final. Note: There is
nothing to submit for Q6 or Q7.
Do not modify function names or image file names
or interpret parameters differently from what is specified! Make sure
your functions follow the expected behavior in terms of type of input
and output: if they return lists, their default return
type must always be list. A
function’s documentation serves, in some way, as a contract
between you and your users. Deviating from this contract makes it hard
for potential users to adopt your implementation!
Functionality and programming style are important, just as both the content and the writing style are important when writing an essay. Make sure your variables are named well, and your use of comments, white space, and line breaks promote readability. We expect to see code that makes your logic as clear and easy to follow as possible.
Do not forget to add, commit, and push your work as it progresses! Test your code often to simplify debugging.
Please edit the README.md file and enter the names
of any appropriate students on the Collaboration line. Add,
commit, and push this change.
Near the bottom of the README.md, there is a
breakdown of the grading expectations that will form the basis of your
lab’s evaluation. Please keep these in mind as you work through your
lab!
Download a .zip archive of your work. Download
your assignment files for submission by going to your lab repository on
Gitlab, selecting the Download source code icon (a down
arrow), and select zip. Doing so should download all of
your lab files into a single zip archive as lab06-main.zip,
and place it inside your Downloads folder (or to whichever folder is set
as your browser’s default download location).
Submit your work. Navigate to the CS134 course on Gradescope. On your Dashboard, select the appropriate Lab Assignment. Drag and Drop your downloaded zip archive of the Lab Assignment from the previous step, and select ‘Upload’.