Lab 8: Dictionaries, Baby Names and Ngrams
This labs focuses on application of dictionaries to two types of data: counts of baby names in the United States by year and counts of baby names referenced in literature by year. Our goal will be to produce a visualization that fuses these two data sources together.
Step 0: Lab Preparation
Step 1: Source Code
- Clone your private repo to an appropriate directory in your home folder
(
~/labsis a good choice):$ git clone https://github.com:williams-cs/<git-username>-lab8.git
Remember, you can always get the repo address by using the ssh copy-to-clipboard link on github. - Once inside your <git-username>-lab8 directory, create a virtual environment using
$ pyvenv venv
Remember to use pyvenv instead of virtualenv. - Activate your environment by typing:
$ . venv/bin/activate
- Use pip to install the pillows imaging library:
$ pip install pillow
- Use pip to install the matplotlib plotting library:
$ pip install matplotlib
- Use pip to install the requests library:
$ pip install requests
- Remember that you must always activate your virtual environment when opening a new terminal
- Type
$ git branch
and notice that you are currently editing the master branch. - Create a new branch with
$ git branch plot
- Checkout this branch by typing
$ git checkout plot
- Any changes you make to the repository are now isolated on this branch.
Data
This lab features two data sources.
- Baby names from social security card applications by year from 1880-2015. This data is included in your repo in the names/ directory. Each year YYYY has a file with the name yobYYYY.txt. Each file is in CSV format. Each row has the format:
NAME,SEX,COUNT
. - Ngram data from the Google Ngram Viewer. Here we will actually make an HTTP request and scrape the data from the result. This data shows what percentage of books in a given year feature the given Ngrams. The data only goes up to 2008!. Requests for newer data will not fail, they will just return less data than you expect. This will likely break assumptions made in your programs, so be careful.
Representing Baby Names
Develop a class called BabyNames in baby.py that encapsulates the counts of baby names for a particular range of years. Besides __init__, your class should support three other methods:
add: update the count associated withname/yearbycountor initialize tocountif it doesn't already exist.count: return the count associated withnameforyear.counts: return the counts associated withnamefor the give list ofyears
class BabyNames:
def __init__(self):
def add(self, name, year, count):
"""
Add 'count' to 'name' in 'year' (or make name/ year have count if
name / year does not yet exist)
"""
def count(self, name, year):
"""Return count associated with name / year"""
def counts(self, name, years):
"""Return a list of counts associated with 'name' for 'years'"""
Here are some implementation notes:
- You probably want to store a dictionary keyed by names whose values are dictionaries keyed by year.
countshould return 0 if the name / year pair does not exist
Step 4: babynames_from_files
In baby.py, write a function called babynames_from_files that creates an instance of BabyNames populated with data from basedir for the given list of years.
def babynames_from_files(basedir, prefix, years):
"""Return a BabyNames object populated from data in 'dir'
for the given years"""
Some implementation notes:
- The
basedirparameter is a directory where files of the formprefixYYYY.txtlive. - You may find the function
os.path.joinhelpful.
>>> import baby
>>> bn = baby.babynames_from_files("./names", "yob", list(range(1900,2001)))
>>> bn.counts("Brent", list(range(1970,1981)))
[4304, 4074, 3556, 3306, 3441, 3387, 3426, 3448, 3202, 3479, 3566]
Step 5: Google Ngrams
Slide on over to the Google Ngram Viewer and try a few searches. You'll notice that the URL is composed of three parts:
https://books.google.com/ngrams/graphgives the base address;?signals that we are about to pass some parameters; andkey1=value1&key2=value2&...&keyN=valueNwhere the key and value strings are encoded properly.
The only key/value pairs that we care about are the following:
- content=Albert+Einstein%2CFrankenstein
- year_start=1800
- year_end=2000
- corpus=17
- smoothing=3
The requests library that we used in Lab 4 has excellent support for making URL requests with key/value parameters.
>>> import requests
>>> params = {"names" : "Brent,Courtney,Oscar,George", "year" : 2012}
>>> r = requests.get("http://www.somewhere.com/foobar", params=params)
>>> print(r.url)
https://www.somewhere.com/foobar?names=Brent%2CCourtney%2COscar%2CGeorge&year=2012
In the file ngrams.py write a function called google_ngram_request that takes a list of strings (the tokens), a start year and a finish year, and returns the underlying response content.
def google_ngram_request(tokens, start_year, end_year)
"""
Return the text of the google ngram results for a list of 'tokens'
starting with 'start_year' and ending with 'end_year'
"""
The function google_ngram_request can be used in conjection with the supplied parse function to extract the given data into a dictionary. Test your code:
>>> ngrams.parse(ngrams.google_ngram_request(['Brent', 'Courtney'], 1970, 1972))
{'Brent': [1.0628228134616318e-06, 1.0628228134616318e-06, 1.0628228134616318e-06],
'Courtney': [1.1416135142402102e-06, 1.1416135142402102e-06, 1.1416135142402102e-06]}
Step 6: Plotting
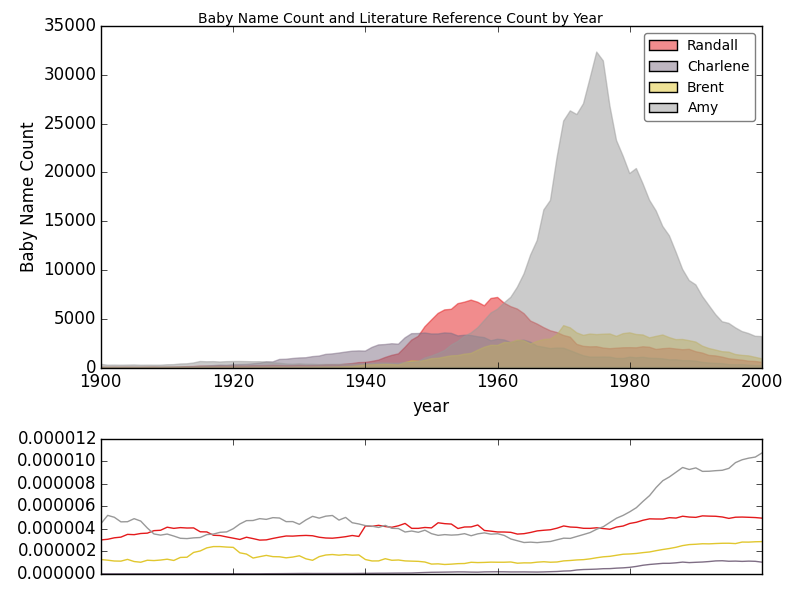
Define a function in baby.py called plot that accepts five arguments:
filenamethe filename in which to output the plot;bnaBabyNamesinstance storing name / year / count data;ngramsa dictionary mapping names to percentages over a range of years;namesa list of names; andyearsa list of years.
This function should construct a plot similar to that shown above and save it in filename. Similar means it should contain all the major characteristics: filled plots, a 2:1 plotting ratio between the top figure and the bottom figure, a legend, proper labels, etc. The color scheme can be slightly different as can some of the font choices and sizes.
Here are some implementation notes:
- Use subplot2grid to create 3 rows and 1 column. Your top plot should occupy 2 rows. Your bottom plot should occupy 1 row. Use the rowspan keyword argument in one of your subplot2grid call to make this possible. Here is the subplot2grid docs.
- Consider making the tick labels on your bottom plot invisible
You can run your code from the command line using
$ python3 baby.py names.png ./names 1900 2000 name1 name2 name3 ...where
./names is the directory where the baby name data is kept.
Step 7: Submission
- Now commit those additions to the repository:
$ git commit -a -m "some log message"
- Push your changes back to github repo:
$ git push
You will probably be asked to type$ git push --set-upstream origin plotwhich you should do. This pushes your iterator branch back up to the GitHub Repo. - Now navigate to your GitHub repo using a web browser. You should see a list of recently pushed branches with links to compare and pull request. Go ahead and issue a PR